-
[Redis] 안정성과 가용성을 위한 클러스터📖 개발 공부/redis 2023. 8. 16. 22:12
목차
1. Redis Cluster 소개
2. 데이터 분산과 key 관리
3. 성능과 가용성
4. 클러스터의 제약사항Redis Cluster
- 여러 노드에 자동적인 데이터 분산할 수 있다.
- 일부 노드의 실패나 통신 단절에도 계속 작동하는 가용성을 제공한다.
- 고성능을 보장하면서 선형 확장성을 제공한다.
Redis Cluster 특징
- full-mesh 구조로 통신한다.
→ 각 노드가 모든 노드와 연결이 되어있는 구조.

- cluster bus라는 추가 채널(port)을 사용한다.
보통 16379를 클러스터 버스로 사용한다. - gossip protocol을 사용한다.
중복된 정보도 주고받을 것이다. (하나의 정보를 여럿 주고받을 것임) → gossip protocol로 통신이 개수를 줄인다. - hash slot을 사용하여 키를 관리한다.
데이터를 노드에 분산하는 방식 (어떤 기준으로 분산시킬지) - DB0만 사용이 가능하다.
redis는 인스턴스 하나에서도 데이터베이스를 나눠 사용할 수 있는데, 클러스터 모드에서는 DB를 나눠쓸 수 없고 1개만 쓸 수 있다. - multi key 명령어가 제한된다.
- 클라이언트는 모든 노드에 접속 가능하다.
Sentinel과의 차이점
- 클러스터는 데이터 분산(샤딩)을 제공한다.
- 클러스터는 자동 장애조치를 위한 모니터링 노드(Sentinel)를 추가 배치할 필요가 없다.
- 클러스터에서는 multi key 오퍼레이션이 제한된다.
- Sentinel은 비교적 단순하고 소규모의 시스템에서 HA가 필요할 때 채택된다.
데이터 분산과 key 관리
데이터를 분산하는 기준
- 특정 key의 데이터가 어느 노드(shard)에 속할 것인지 결정하는 메커니즘이 있어야 한다.
- 보통 분산 시스템에서 해싱이 사용된다.
- 단순 해싱으로는 노드의 개수가 변할 때 모든 매핑이 새로 계산되어야 하는 문제가 있다.

어떤 노드에 키가 들어가야할지 결정해야 한다.
노드가 하나 추가됐을 때, 나머지를 구할 때 기준값이 2 → 3이 된다.
hash(”user:a”) % 2 → hash(”user:a”) % 3그러면 이미 기존에 들어가있던 키들이 영향을 받게 된다. 원래는 0번 노드에서 처리해야했던 애들이 다른 노드로 처리되어야하게 된다.
이는 너무 비효율적이다.
그렇기 때문에, 노드 개수가 변할 때 나머지 노드들의 영향이 최소한으로 가야한다.
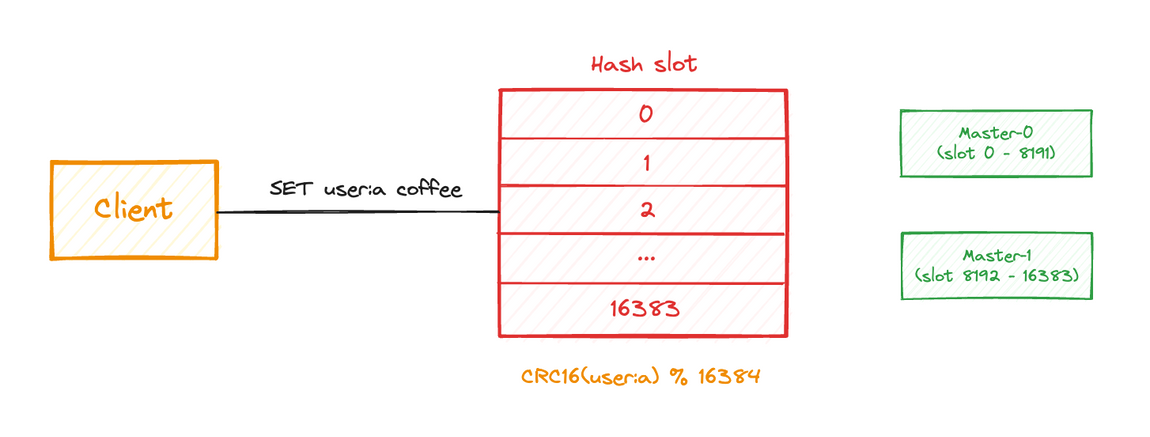
redis cluster에서는 Hash Slot을 이용하여 데이터를 분산한다. 중간에 hash slot이라는 추가적인 개념을 만들어놓고, 특정 키를 hash slot에 매핑 시키고, hash slot을 각 노드에 배분하는 방식으로 해결한다.
Hash Slot을 이용한 데이터 분산
- 총 16,384개의 hash slot으로 key 공간을 나누어 관리한다.
- 각 키는 CRC16 해싱 후, 16,384로 modulo 연산을 하여 각 hash slot에 매핑한다.
- hash slot은 각 노드들에게 나누어 분배된다.
노드 개수에 따라서 해시 슬롯을 나눠가지게 된다.
여기서 노드가 하나 추가된다고 해보자.
추가되면, 해시 슬롯을 기존의 노드들에서 일부를 넘겨주게 되는 것이다. 그러면 변경이 생기는 해시슬롯에 속했던 키만 영향을 받고, 다른 해시 슬롯에 속한 데이터들은 그대로 노드에 존재하게 된다.
그래서 필요한 만큼의 오버헤드만 감수하게 된다.
각각의 노드에 데이터가 배분되어있을 때 어떻게 접근할 수 있는지 보자.
클라이언트의 데이터 접근
클라이언트는 모든 클러스터에 붙어야한다. 클러스터 노드가 6개가 있으면 그 6개 정보를 클라이언트가 다 알고있어야 하고 접속되어있어야 한다.
- 클러스터 노드는 요청이 온 key에 해당하는 노드로 자동 redirect를 해주지 않는다.
- 클라이언트는 MOVED 에러를 받으면 해당 노드로 다시 요청해야 한다.

다음과 같이 해당 노드가 담당하는 slot이 아니므로 MOVED 에러를 받고, 클라이언트는 다음 응답으로 올바른 노드로 재시도를 할 수 있다. (응답에서 서빙하는 진짜 노드의 주소를 알려준다.)
(error) MOVED 160000 127.0.0.1:7005클라이언트 재시도가 일어나는 경우는 그렇게 많지 않다. 왜냐하면 클라이언트가 키값과 노드의 매핑 테이블을 캐싱하고 있기 때문이다.
(한번 매핑 테이블을 만들어 놓으면 보통 변하지 않고, 장애가 났거나 노드가 추가/삭제 될 때 업데이트를 해주면 보통 바뀔 일이 별로 없다. 평소엔 재시도가 일어나지않는다고 보면 된다.)
성능과 가용성
클러스터를 사용할 때의 성능
- 클라이언트가 MOVED 에러에 대해 재요청을 해야 하는 문제
→ 클라이언트(라이브러리)는 key-node 맵을 캐싱하므로 대부분의 경우는 발생하지 않는다. - 그렇기에 클라이언트는 싱글 인스턴스의 Redis를 이용할 때와 같은 성능으로 이용이 가능하다.
- 분산 시스템에서 성능은 데이터 일관성(consistency)과 trade-off가 있다.
→ Redis Cluster는 고성능의 확장성을 제공하면서 적절한 수준의 데이터 안정성과 가용성을 유지하는 것을 목표로 설계되었다.
실제로는 Cluster가 싱글 인스턴스 사용할 때만큼 데이터 안정성을 제공하지 않는다. 하지만 적절한 수준해서 타협한다.
클러스터의 데이터 일관성
- Redis Cluster는 strong consistency를 제공하지 않는다.
strong consistency: 복제로 인한 단점이 1도 없는 방식이다. 모든 클라이언트가 모든 노드에서 언제나 100% 동일한 데이터를 볼 수 있다. - 높은 성능을 위해 비동기 복제를 하기 때문이다.
여기서 데이터 일관성이 깨질 수 있다.

Ack과 복제는 순서가 정해져 있지 않으므로, 복제가 완료되기 전에 master가 죽으면 데이터는 유실된다.
클러스터의 가용성 - auto failover
- 일부 노드(master)가 실패(또는 네트워크 단절) 하더라도 과반수 이상의 master가 남아있고, 사라진 master의 replica들이 있다면 클러스터는 failover되어 가용한 상태가 된다.
- node timeout 동안 과반수의 master와 통신하지 못한 master는 스스로 error state로 빠지고 write 요청을 받지 않는다.
- 예시) master1과 replica2가 죽더라도, 2/3의 master가 남아있고, master1이 커버하던 hash slot은 replica1이 master로 승격되어 커버할 수 있다.
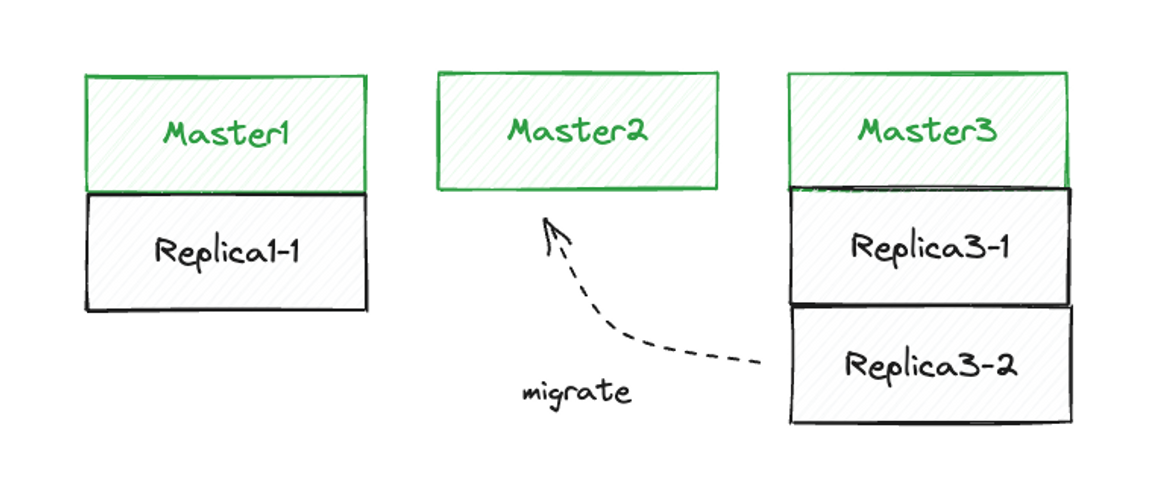
클러스터의 가용성 - replica migration
- replica가 다른 master가 migrate해서 가용성을 높인다.
- 예시) master3는 replica 1개를 빼도 1개가 남기 때문에 replica 3-2는 다른 master로 migrate가 가능하다.
클러스터의 제약 사항
클러스터에서는 DB0만 사용 가능하다
- Redis는 한 인스턴스에 여러 데이터베이스를 가질 수 있으며 디폴트트 16
설정: databases 16 - Multi DB는 용도별로 분리해서 관리를 용이하게 하기 위한 목적이다.
- 장점) 수치, 메트릭같은 거 뽑아낼 수 있고, 애플리케이션별로 격리 가능
- 하지만, 실제로 그렇게 많이 쓰이지 않는다.
- 클러스터에서는 해당 기능을 사용할 수 없고 DB0으로 고정된다.
Multi key operation 사용의 제약
- key들이 각각 다른 노드에 저장되므로 MSET과 같은 multi-key operation은 기본적으로 사용할 수 없다.
- 같은 노드 안에 속한 key들에 대해서는 multi-key operation이 가능하다.
- hash tags 기능을 사용하면 여러 key들을 같은 hash slot에 속하게 할 수 있다.
→ key 값중 “{}” 안에 들어간 문자열에 대해서만 해싱을 수행하는 원리이다. - MSET {user:a}:age 20 {user:a}:city seoul
{user:a} → user:a라는 스트링의 해싱된 결과의 해시 슬롯에 속하게 되어서 결과적으로 두 키가 동일한 해시슬롯에 들어가게 된다.
클러스터 구현의 강제
- 클라이언트는 클러스터의 모든 노드에 접속해야 한다.
- 클라이언트는 redirect 기능을 구현해야 한다 (MOVED 에러의 대응)
- 클라이언트 구현이 잘 된 라이브러리가 없는 환경도 있을 수 있다.
반응형'📖 개발 공부 > redis' 카테고리의 다른 글
[Redis] Redis의 Data Type 공부 (Strings, Lists, Sets, Hashes, Sorted Sets, Bitmaps, HyperLogLog) (0) 2023.08.06 [Redis] Redis 소개와 특징 (0) 2023.08.04