-
Spring Batch Partitioning로 대용량 데이터 마이그레이션 최적화 및 롱 트랜잭션 해결📖 개발 공부 2024. 12. 22. 21:58
Spring Batch Partitioning 도입
이번 프로젝트에서 400만개 데이터 대상으로 마이그레이션 작업을 수행해야 했다.
기존에는 하나의 스레드에서 Reader, Processor, Writer를 순차적으로 처리했기 때문에, 대용량 데이터를 다루기에는 시간이 너무 오래 걸리는 문제가 있었다. (거의 5시간 이상이 걸렸다)
그래서 이번에 id 기반으로 데이터를 파티션으로 분할하고, 각 파티션에서 병렬로 Reader/Processor/Writer를 동작하도록 파티셔닝 방식을 적용했다.
파티셔닝 방식은 다음과 같은 장점이 있다.
- 독립적인 실행: 각 파티션은 독립적으로 실행되므로, 특정 파티션에서 오류가 발생해도 다른 파티션 작업에는 영향을 주지 않는다.
- 효율적인 에러 관리: 각 파티션의 상태와 데이터 범위를 명확히 알 수 있어, 실패하거나 재처리가 필요한 경우 해당 파티션 범위 내 데이터만 핸들링할 수 있다.
구현 코드를 간략히 공유해보려고 한다.
나는 DBColumnRangePartitioner 클래스를 만들어, 특정 테이블이 아닌 여러 테이블에서 파티셔닝 방식을 사용할 수 있도록 범용화해두었다.
var start = minId for (i in 0 until gridSize) { val end = Math.min(start + targetSize - 1, maxId) val context = ExecutionContext() log.info { "partitionNumber: $i - minId: $start, maxId: $end" } context.put("minId", start) context.put("maxId", end) partitions["partition$i"] = context start += targetSize }이렇게 각 파티션별 minId, maxId를 구하여서 stepExecutionContext에 등록을 해둔다.
그 후 위에서 등록한 minId, maxId를 reader에서 조회하여 쿼리한다.
@Bean @StepScope fun reader( @Value("#{jobParameters[kstNow]}") kstNow: String?, @Value("#{stepExecutionContext[minId]}") minId: Long?, @Value("#{stepExecutionContext[maxId]}") maxId: Long?, ): JdbcPagingItemReader<ExampleEntity> { val queryProvider = SqlPagingQueryProviderFactoryBean() .apply { setDataSource(ugcDataSource) setSelectClause("*") setFromClause("example_table") setWhereClause("id BETWEEN $minId AND $maxId") // 정렬 키 설정 val sortKeys: MutableMap<String, Order> = HashMap() sortKeys["id"] = Order.ASCENDING setSortKeys(sortKeys) } return JdbcPagingItemReaderBuilder<ExampleEntity>() .name("reader") .dataSource(dataSource) .queryProvider(queryProvider.`object`) .fetchSize(CHUNK_SIZE) .rowMapper(..) .build() }자세한 내용은 jojoldu님 블로그를 참고해보자! (이 블로그로 도움을 많이 받았다 ㅎㅎ)
Spring Batch 파티셔닝 (Partitioning) 활용하기
지난 시간에 소개 드린 멀티쓰레드 Step과 더불어 파티셔닝 (Partitioning)은 Spring Batch의 대표적인 Scalling 기능입니다. 서비스에 적재된 데이터가 적을 경우에는 Spring Batch의 기본 기능들만 사용해도
jojoldu.tistory.com
한편, 단일 스텝 내에서 멀티스레드를 사용하는 방식으로도 병렬 처리를 구현할 수 있다.
그러나 이 방식은 병렬 처리 단위에서 Reader가 공유되며, Processor/Writer만 병렬로 동작한다. 이는 Reader가 전체 데이터를 관리하기 때문에, 에러가 발생하면 작업 전반에 영향을 줄 수 있다.
반면, 파티셔닝 방식은 각 파티션이 독립적으로 동작하므로, 특정 파티션에서 에러가 발생해도 해당 파티션만 재실행할 수 있다는 큰 차이점이 있다.
파티셔닝 방식 도입후, 400만개 데이터를 1시간 내에 처리할 수 있었다! 👍
JdbcCursorItemReader에서 Long Transaction 문제
파티셔닝을 적용한 후, JdbcCursorItemReader를 통한 데이터 읽기 방식으로 인한 Long Transaction 문제가 발생했다.
이는 JDBC 드라이버 ResultSet 동작 방식과 연관되어있다.

DB 연결 시에 특별한 옵션을 설정하지 않은 경우에는
위와 같이 ResultsetRowsStatic 객체가 할당되고, rowData의 rows에 모든 데이터를 담고 있는 것을 알 수 있다.@Bean @StepScope fun reader( @Value("#{jobParameters[kstNow]}") kstNow: String?, ): JdbcCursorItemReader<ExampleEntity> { val query = """ SELECT * FROM example_table ORDER BY id """.trimIndent() log.info { query } val builder = JdbcCursorItemReaderBuilder<ExampleEntity>() .name("reader") .dataSource(dataSource) .sql(query) .fetchSize(100) // this .rowMapper(..) .build() }ItemReader를 이렇게 100개로 Fetch size를 설정했지만, 이와 관계없이 모든 데이터를 가져오고 있는 것이다.
JDBC 드라이버는 이렇게 모든 데이터를 가져온 후, 코드에서 ResultSet.next() 를 수행하면 데이터 중 하나의 로우씩 반환한다.
이로 인해
- 모든 데이터를 메모리에 적재하여 메모리 부족 문제가 발생할 수 있고,
- 데이터를 모두 처리할 때까지 트랜잭션을 유지하므로, 데이터베이스 커넥션이 오랜 시간 점유될 수 있다.
그렇기 때문에 가져온 전체 데이터 처리하기까지 트랜잭션을 유지해서, 데이터가 많은 운영 환경에서 롱 트랜잭션이 발생한 것이다.
Resolution: Long Transaction 문제 해결
useCursorFetch 활성화
롱트랜잭션을 해결하는 방법은 다음과 같이 DB 연결시 useCursorFetch 옵션을 추가하는 것이다!
"jdbc:mysql://~?useCursorFetch=true"이 옵션을 추가하면 애플리케이션에서는 DB 서버로부터 정해진 Fetch 사이즈만큼 데이터를 가져오게 된다.

위와 같이 ResultsetRowsCursor 객체가 할당되고, fetchedRows라는 arrayList에 100개의 데이터셋이 담긴 걸 볼 수 있다.
verifyCursorPosition 비활성화
이때 나 같은 경우엔 verifyCursorPosition 를 false로 설정해야 정상 동작했다.
@Bean @StepScope fun reader( @Value("#{jobParameters[kstNow]}") kstNow: String?, ): JdbcCursorItemReader<ExampleEntity> { val query = """ SELECT * FROM example_table ORDER BY id """.trimIndent() log.info { query } val builder = JdbcCursorItemReaderBuilder<ExampleEntity>() .name("reader") .dataSource(dataSource) .sql(query) .fetchSize(100) .verifyCursorPosition(false) // this - 커서 검증 비활성화 .rowMapper(..) .build() }위 옵션을 설정하지 않고 배치를 수행하면,
"org.springframework.dao.InvalidDataAccessResourceUsageException: Unexpected cursor position change."
다음과 같은 에러가 발생하며 실패한다.
해당 설정을 해야하는 이유가 궁금해서 verifyCursorPosition 내부 로직들을 살펴봤다!


코드를 보면 this.getCurrentItemCount()과 resultSet의 getRow() 값이 다르면 InvalidDataAccessResourceUsageException 예외를 던지고 있다.

getRow 설명을 보면 첫번째 행을 1, 두번째 행을 2, .. 이렇게 반환하고 있다. 즉, 이론적으로 보면 개수를 반환하는 CurrentItemCount값과 같을 수 밖에 없다.
하지만 내부 구현을 보니, 이상한 점을 발견했다 👀
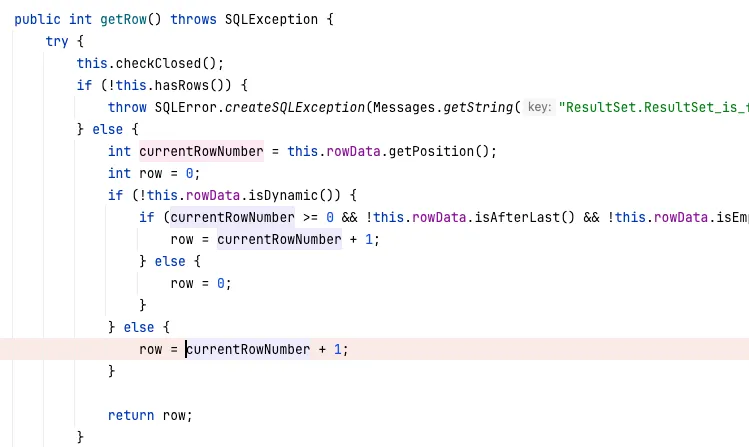
ResultSetImpl에 구현된 getRow() 
ResultsetRowsCursor의 getPosition() ResultSetImpl에 구현된 getRow() 메서드, ResultsetRowsCursor의 getPosition()을 보자.
getPosition()에서 currentPositionInEntireResult(값: 0)에서 1을 더했다.
그리고 getRow()에서 getPosition()의 반환값을 currentRowNumber 변수에 할당하고, currentRowNumber에 1을 추가로 더했다.
그렇기 때문에 getCurrentItemCount()가 1이면, getRow()는 2이기 때문에 expectedCurrentRow != (long)this.rs.getRow() 조건에 걸려 예외가 던져진 것이다.

ResultsetRowsCursor가 아닌 ResultsetRowsStatic에서 구현된 getPosition()을 보니currentRowNumber에 1을 더하지 않고 있다.

ResultsetRowsStatic의 getPosition() 그래서 특정 구현체에서만 이런 버그가 난다고 생각했다.
나와 비슷한 이슈를 가진 스택오버플로우를 찾아봤는데
InvalidDataAccessResourceUsageException: Unexpected cursor position change
Encountered the following exception when trying to read from Database in a Spring Batch Application. Any insight would be helpful. This is caused when using a JdbcCursorItemReader. The application ...
stackoverflow.com
위 답변들을 보니 드라이버마다 getRow()를 반환하는 방법이 달라서인 것 같다
결론은, verifyCursorPosition를 false로 설정하여 ResultSet.getRow()와 getCurrentItemCount()의 불일치로 발생하는 예외를 방지했다!
이번 프로젝트에서 Partitioner을 활용해서 대용량 데이터 마이그레이션 작업 시간을 단축할 수 있었다. 또한 롱트랜잭션 문제를 알아보고 해결하여 JDBC 동작 방식을 더 이해할 수 있었다! 👍
🔗 참고
Spring Batch 파티셔닝 (Partitioning) 활용하기
지난 시간에 소개 드린 멀티쓰레드 Step과 더불어 파티셔닝 (Partitioning)은 Spring Batch의 대표적인 Scalling 기능입니다. 서비스에 적재된 데이터가 적을 경우에는 Spring Batch의 기본 기능들만 사용해도
jojoldu.tistory.com
mysql-connector-j/src/main/protocol-impl/java/com/mysql/cj/protocol/a/result/ResultsetRowsStreaming.java at release/8.x · mysql
MySQL Connector/J. Contribute to mysql/mysql-connector-j development by creating an account on GitHub.
github.com
mysql-connector-j/src/main/protocol-impl/java/com/mysql/cj/protocol/a/result/ResultsetRowsCursor.java at release/8.x · mysql/my
MySQL Connector/J. Contribute to mysql/mysql-connector-j development by creating an account on GitHub.
github.com
반응형'📖 개발 공부' 카테고리의 다른 글
Spring Boot에서 Google Vertex AI Gemini 연동하기 (0) 2025.03.16 메시지 큐 비교하기 (RabbitMQ, Kafka, SQS, Redis Pub/Sub) (0) 2025.02.02 Hikari CP 설정 알아보기 (0) 2024.11.24 Spring 트랜잭션 롤백 관리: rollback-only 이슈 분석과 해결 (3) 2024.11.10 The SAGA Pattern (0) 2024.09.29
